Regularni izrazi (skraćeno – regex) koji se koriste za pretraživanje i pravila segmentacije su oni koje podržava Java. Više konkretnih podataka možete pronaći u dokumentaciji o regularnim izrazima u Javi. Dodatne upute i primjeri slijede u daljnjem tekstu.
Note
Ovo je poglavlje namijenjeno naprednim korisnicima koji trebaju mogućnost određivanja vlastitih varijanti pravila segmentacije ili složenije i efikasnije načine pretraživanja.
Table 17.1. Regex – indikatori
| Konstrukt | ...odgovara sljedećem |
|---|---|
| (?i) | omogućavanje podudaranja bez razlikovanja veličine slova (prema zadanim vrijednostima uzorak razlikuje velika i mala slova) |
Table 17.2. Regex – znak
| Konstrukt | ...odgovara sljedećem |
|---|---|
| x | znak x, osim u sljedećim slučajevima... |
| \uhhhh | znak heksadecimalne vrijednosti 0xhhhh |
| \t | znak tabulatora ('\u0009') |
| \n | znak novoga retka ('\u000A') |
| \r | znak kraja retka ('\u000D') |
| \f | znak nove stranice ('\u000C') |
| \a | znak zvona ('\u0007') |
| \e | prekidni znak ('\u001B') |
| \cx | kontrolni znak koji odgovara znaku x |
| \0n | znak oktalne vrijednosti 0n (0 <= n <= 7) |
| \0nn | znak oktalne vrijednosti 0nn (0 <= n <= 7) |
| \0mnn | znak oktalne vrijednosti 0mnn (0 <= m <= 3, 0 <= n <= 7) |
| \xhh | znak heksadecimalne vrijednosti 0xhh |
Table 17.3. Regex – citat
| Konstrukt | ...odgovara sljedećem |
|---|---|
| \ | ništa, ali citira sljedeći znak; potreban je kada želite upisati neki od metaznakova !$()*+.<>?[\]^{|} da predstavljaju same sebe |
| \\ | primjera radi, ovo je znak obrnute kose crte |
| \Q | ništa, ali citira sve znakove do \E |
| \E | ništa, ali okončava citiranje započeto s \Q |
Table 17.4. Regex – klase za blokove i kategorije Unicode
| Konstrukt | ...odgovara sljedećem |
|---|---|
| \p{InGreek} | znak u grčkome bloku (jednostavni blok) |
| \p{Lu} | veliko slovo (jednostavna kategorija) |
| \p{Sc} | simbol valute |
| \P{InGreek} | bilo koji znak osim znaka iz grčkoga bloka (negacija) |
| [\p{L}&&[^\p{Lu}]] | bilo koje slovo osim velikih slova (oduzimanje) |
Table 17.5. Regex – klase znakova
| Konstrukt | ...odgovara sljedećem |
|---|---|
| [abc] | a, b ili c (jednostavna klasa) |
| [^abc] | bilo koji znak osim a, b ili c (negacija) |
| [a-zA-Z] | a do z ili A do Z, uključujući navedena slova (raspon) |
Table 17.6. Regex – unaprijed određene klase znakova
| Konstrukt | ...odgovara sljedećem |
|---|---|
| . | bilo koji znak (osim onih za okončanje retka) |
| \d | znamenka: [0-9] |
| \D | nije znamenka: [^0-9] |
| \s | znak bjeline: [ \t\n\x0B\f\r] |
| \S | nije praznina: [^\s] |
| \w | znak riječi: [a-zA-Z_0-9] |
| \W | nije riječ: [^\w] |
Table 17.7. Regex – granični podudarivači
| Konstrukt | ...odgovara sljedećem |
|---|---|
| ^ | početak retka |
| $ | kraj retka |
| \b | granica riječi |
| \B | granica svega osim riječi |
Table 17.8. Regex – pohlepni kvantifikatori
| Konstrukt | ...odgovara sljedećem |
|---|---|
| X? | X, jednom ili nijednom |
| X* | X, nula ili više puta |
| X+ | X, jednom ili više puta |
Note
Pohlepni kvantifikatori pokušavaju pronaći što je moguće više podudaranja. Primjerice, a+ pronalazi aaa u aaabbb.
Table 17.9. Regex – reluktantni (nepohlepni) kvantifikatori
| Konstrukt | ...odgovara sljedećem |
|---|---|
| X?? | X, jednom ili nijednom |
| X*? | X, nula ili više puta |
| X+? | X, jednom ili više puta |
Note
Nepohlepni kvantifikatori pokušavaju pronaći što je moguće manje podudaranja. Primjerice, a+? pronalazi prvo slovo a u aaabbb.
Table 17.10. Regex – logički operatori
| Konstrukt | ...odgovara sljedećem |
|---|---|
| XY | X nakon kojega slijedi Y |
| X|Y | ili X ili Y |
| (XY) | XY kao jedna skupina |
Za sastavljanje i testiranje regularnih izraza dostupno je više interaktivnih alata. U načelu djeluju prema manje-više jednakome obrascu (na sljedećoj slici možemo vidjeti primjer alata Regular Expression Tester): regularnim izrazom (prvo polje) analizira se tekst i pronalaze tražene vrijednosti koje se prikazuju u tekstnome okviru rezultata.
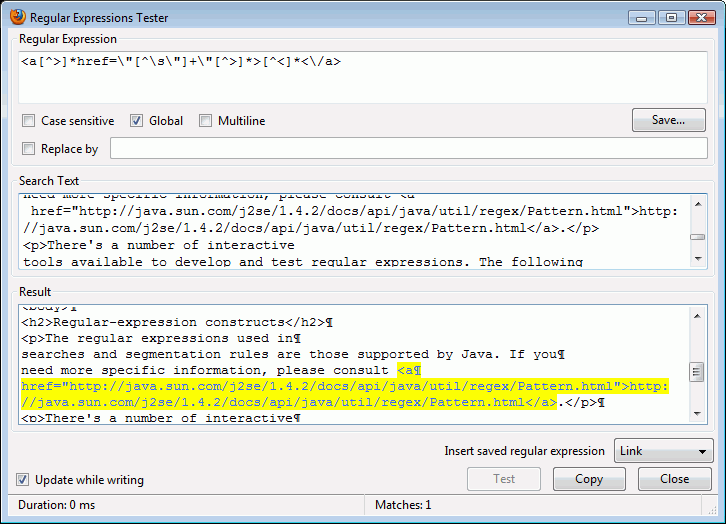
Za sustave Windows, Linux i FreeBSD postoji i samostalni alat The Regex Coach. Funkcionira uglavnom na isti način kao što je to prikazano u gornjemu primjeru.
I sȃm program OmegaT nudi dobru zbirku korisnih regularnih izraza (pogledajte izbornik Mogućnosti > Segmentacija). Na sljedećem popisu imamo izraze koji mogu biti korisni pri pretraživanju prijevodne memorije.
Table 17.11. Regex – primjeri regularnih izraza u prijevodima
| Regularni izraz | Za pronalaženje sljedećega: |
|---|---|
| (\b\w+\b)\s\1\b | dvostruke riječi |
| [\.,]\s*[\.,]+ | zarez ili točka, nakon čega slijede razmaci pa još jedan zarez ili točka |
| \. \s+$ | dodatni razmaci nakon točke na kraju retka |
| \s+a\s+[aeiou] | engleski: ispred riječi koje počinju samoglasnicima u načelu se treba nalaziti neodređeni član „an”, a ne „a” |
| \s+an\s+[^aeiou] | engleski: provjera na istome načelu kao gornja, osim što se radi o riječima koje počinju suglasnicima („a”, a ne „an”) |
| \s{2,} | više od jednoga razmaka |
| \.[A-Z] | točka nakon koje slijedi veliko slovo – moguće je da nedostaje razmak između točke i početka nove rečenice |
| \bis\b | traženje „is”, a ne „this” ili „isn't” itd. |