Regulární výrazy (uváděné i zkráceně jako ‚regex‘ – z anglického ‚REGular EXpressions‘) používané při vyhledávání a v segmentačních pravidlech jsou identické s těmi, které podporuje Java. Pokud potřebujete bližší informace, navštivte stránku Java Regex documentation. Projděte si dodatečné odkazy a příklady níže.
Note
Tato kapitola se obrací především na pokročilé uživatele, kteří potřebují definovat vlastní varianty pravidel segmentace nebo chtějí získat komplexnější a účinnější nástroj při vyhledávání.
Table 17.1. Regulární výrazy – Označení
| Pojem ... | ... znamená: |
|---|---|
| (?i) | Umožňuje hledání bez ohledu na velikost písmen (ve výchozím nastavení se rozlišují velká a malá písmena). |
Table 17.2. Regulární výrazy – Znak
| Pojem ... | ... znamená: |
|---|---|
| x | Znak x, s výjimkou následujících... |
| \uhhhh | Znak s hexadecimální/šestnáctkovou hodnotou 0xhhhh |
| \t | Znak tabulátoru (‚\u0009‘) |
| \n | Znak nového řádku (konce řádku) (‚\u000A‘) |
| \r | Znak návratu vozíku (‚\u000D‘) |
| \f | Znak posunu o stránku (‚\u000C‘) |
| \a | Znak zvukové signalizace (‚\u0007‘) |
| \e | Znak změny (‚\u001B‘) |
| \cx | Řídící znak odpovídající x |
| \0n | Znak s oktalovou/osmičkovou hodnotou 0n (0 <= n <= 7) |
| \0nn | Znak s oktalovou/osmičkovou hodnotou 0nn (0 <= n <= 7) |
| \0mnn | Znak s oktalovou/osmičkovou hodnotou 0mnn (0 <= m <= 3, 0 <= n <= 7) |
| \xhh | Znak s hexadecimální/šestnáctkovou hodnotou 0xhh |
Table 17.3. Regulární výrazy – Uvozování
| Pojem ... | ... znamená: |
|---|---|
| \ | Lomítko samo o sobě neznamená nic, jen uvozuje následující znak. Je vyžadováno, pokud byste chtěli zadání metaznaků !$()*+.<>?[\]^{|} tak, aby odpovídaly samy sobě. |
| \\ | Například toto je znak pro hledání zpětného lomítka |
| \Q | Nic neznamená, vymezuje všechny znaky až po \E |
| \E | Nic neznamená, ukončuje vymezení započaté pomocí \Q |
Table 17.5. Regulární výrazy – Třídy znaků
| Pojem ... | ... znamená: |
|---|---|
| [abc] | a, b, nebo c (jednoduchá třída) |
| [^abc] | Jakýkoliv znak mimo a, b, nebo c (negace) |
| [a-zA-Z] | a až po z nebo A až po Z, včetně (rozsah) |
Table 17.6. Regulární výrazy – Předdefinované třídy znaků
| Pojem ... | ... znamená: |
|---|---|
| . | Jakýkoliv znak (kromě znaků ukončujících řádek) |
| \d | Číslice: [0-9] |
| \D | Ne-číslice: [^0-9] |
| \s | Netisknutelný znak (např. mezera): [ \t\n\x0B\f\r] |
| \S | Negace bílého znaku (např. ne-mezera): [^\s] |
| \w | Znak slova: [a-zA-Z_0-9] |
| \W | Znak ne-slova: [^\w] |
Table 17.7. Regulární výrazy - Označení hranic
| Pojem ... | ... znamená: |
|---|---|
| ^ | Začátek řádku |
| $ | Konec řádku |
| \b | Hranice slova |
| \B | Hranice ne-slova |
Table 17.8. Regulární výrazy – Hladové kvantifikátory
| Pojem ... | ... znamená: |
|---|---|
| X? | X, jednou nebo vůbec |
| X* | X, nula nebo vícekrát |
| X+ | X, jednou nebo vícekrát |
Note
Hladové kvantifikátory se budou snažit najít tolik shody, jak je to jen možné. Například: a+ bude odpovídat aaa v aaabbb
Table 17.9. Regulární výrazy – Líné kvantifikátory
| Pojem ... | ... znamená: |
|---|---|
| X?? | X, jednou nebo vůbec |
| X*? | X, nula nebo vícekrát |
| X+? | X, jednou nebo vícekrát |
Note
Líné kvantifikátory se budou snažit najít co nejmíň shody, jak je to jen možné. Například: a+? bude odpovídat prvnímu a v aaabbb
Table 17.10. Regulární výrazy – Logické operátory
| Pojem ... | ... znamená: |
|---|---|
| XY | X následované Y |
| X|Y | Buď X anebo Y |
| (XY) | XY jako samostatná skupina |
Existuje množství interaktivních nástrojů dostupných pro vývoj a testování regulárních výrazů. Všechny obecně postupují dle stejného vzoru (vizte níže příklad ve formě pluginu pro Firefox: Regular Expression Tester): regulární výraz (záznam nahoře) zkoumá hledaný text (textové pole uprostřed), ukazuje výsledky v poli pro výsledky.
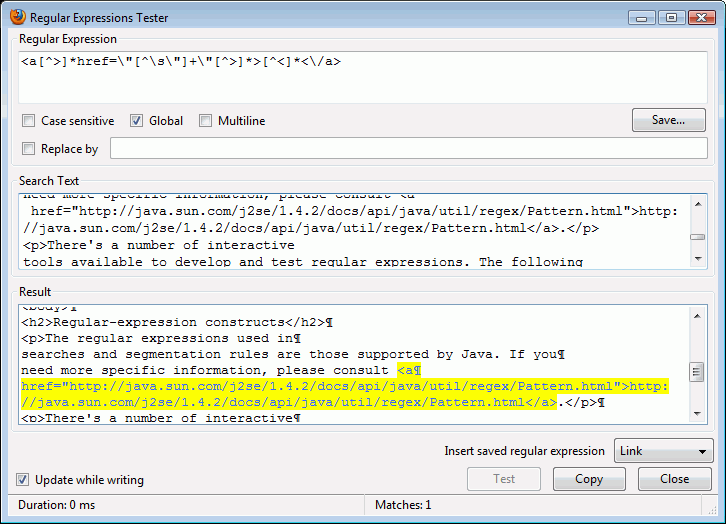
Můžete také vyzkoušet trenažer The Regex Coach jako samostatný nástroj pro Windows, Linux, Mac, FreeBSD. Je podobný předchozímu příkladu.
Malá sbírka užitečných regulárních výrazů se nachází přímo v aplikaci OmegaT (vizte Možnosti > Segmentace). Následující seznam zahrnuje výrazy, které se mohou hodit při prohledávání překladové paměti:
Table 17.11. Regulární výrazy Příklady regulárních výrazů v překladech
| Regulární výraz | najde následující: |
|---|---|
| (\b\w+\b)\s\1\b | zdvojený výskyt slova |
| [\.,]\s*[\.,]+ | čárka nebo tečka následovaná mezerou a další čárkou nebo mezerou |
| \. \s+$ | mezery navíc, za nimiž je tečka na konci řádku |
| \s+a\s+[aeiou] | Pro angličtinu: u slov začínajících na samohlásku se užívá neurčitý člen „an“, ne „a“ |
| \s+an\s+[^aeiou] | Pro angličtinu: stejná kontrola jako nahoře, ale pro souhlásky („a“, ne „an“) |
| \s{2,} | víc než jedna mezera |
| \.[A-Z] | Tečka následovaná slovem s prvním velkým písmenem – pravděpodobně chybí mezera mezi tečkou a začátkem nové věty? |
| \bis\b | hledej „is“, ale ne „this“ nebo „isn't“ atd. |