Le espressioni regolari (regex, in breve) ammesse per le operazioni di ricerca sono quelle riconosciute da Java. Per ulteriori e più specifiche informazioni, consultare la documentazione Java Regex. Vedere più avanti per ulteriori riferimenti ed esempi.
Note
Questo capitolo si rivolge agli utenti avanzati, che hanno la necessità di definire le proprie varianti delle regole di segmentazione o costruire combinazioni di ricerca più complesse ed efficaci.
Table 17.1. Regex - Flag
| Il costrutto | ...corrisponde al seguente |
|---|---|
| (?i) | Consente di avviare una ricerca che non consideri le lettere maiuscole e minuscole (per impostazione predefinita, il modello distingue tra maiuscole e minuscole). |
Table 17.2. Regex - Carattere
| Il costrutto | ...corrisponde al seguente |
|---|---|
| x | Viene rilevato il carattere corrispondente a x, ma con le seguenti eccezioni... |
| \uhhhh | Viene rilevato il carattere col valore esadecimale 0xhhhh |
| \t | Carattere di tabulazione ('\u0009') |
| \n | Carattere corrispondente a un avanzamento di riga (line feed, LF) ('\u000A') |
| \r | Carattere corrispondente a un ritorno di carrello (carriage-return, CR) ('\u000D') |
| \f | Carattere corrispondente all'inizio di una nuova pagina in una stampa (form feed) ('\u000C') |
| \a | Carattere di controllo bell ('\u0007') |
| \e | Carattere escape ('\u001B') |
| \cx | Carattere di controllo corrispondente a x |
| \0n | Carattere col valore ottale 0n (0 <= n <= 7) |
| \0nn | Carattere col valore ottale 0nn (0 <= n <= 7) |
| \0mnn | Carattere col valore ottale 0mnn (0 <= m <= 3, 0 <= n <= 7) |
| \xhh | Carattere col valore esadecimale 0xhh |
Table 17.3. Regex - Citazione
| Il costrutto | ...corrisponde al seguente |
|---|---|
| \ | Nulla, se non il carattere immediatamente successivo. È necessario quando si desidera usare i metacaratteri !$()*+.<>?[\]^{|} in modo che vengano utilizzati come caratteri e non come operatori. |
| \\ | Per esempio, questa combinazione corrisponde al carattere della barra rovesciata (“ \ ”). |
| \Q | Nulla, ma indica tutti i caratteri fino a \E |
| \E | Nulla, ma conclude la citazione iniziata da \Q |
Table 17.4. Regex - Classi per blocchi e categorie Unicode
| Il costrutto | ...corrisponde al seguente |
|---|---|
| \p{InGreek} | Carattere nel blocco greco ( blocco semplice) |
| \p{Lu} | Lettera maiuscola ( categoria semplice) |
| \p{Sc} | Simbolo di valuta |
| \P{InGreek} | Qualsiasi carattere, eccetto uno nel blocco greco (negazione) |
| [\p{L}&&[^\p{Lu}]] | Qualsiasi lettera, eccetto una lettera maiuscola (sottrazione) |
Table 17.5. Regex - Classi di carattere
| Il costrutto | ...corrisponde al seguente |
|---|---|
| [abc] | a, b o c (classe semplice) |
| [^abc] | Qualsiasi carattere, eccetto a, b o c (negazione) |
| [a-zA-Z] | Da "a" a "z" o da "A" a "Z", inclusi (intervallo) |
Table 17.6. Regex - Classi di carattere predefinite
| Il costrutto | ...corrisponde al seguente |
|---|---|
| . | Qualsiasi carattere (eccetto i terminatori di riga) |
| \d | Una cifra: [0-9] |
| \D | Un carattere non numerico: [^0-9] |
| \s | Un carattere di spazio bianco: [ \t\n\x0B\f\r] |
| \S | Un carattere che non sia uno spazio bianco: [^\s] |
| \w | Un carattere parola: [a-zA-Z_0-9] |
| \W | Un carattere non-parola: [^\w] |
Table 17.7. Regex - Rilevatori di limitazione
| Il costrutto | ...corrisponde al seguente |
|---|---|
| ^ | Inizio di una riga |
| $ | Fine di una riga |
| \b | Limite di una parola |
| \B | Limite di una non-parola |
Table 17.8. Regex - Quantificatori di ripetizione
| Il costrutto | ...corrisponde al seguente |
|---|---|
| X? | X, una sola volta oppure nessuna |
| X* | X, zero o più volte |
| X+ | X, una o più volte |
Note
i quantificatori di ripetizione rileveranno tutte le ripetizioni possibili. Per esempio, a+ rileverà aaa in aaabbb
Table 17.9. Regex - Quantificatori riluttanti (non ripetitivi)
| Il costrutto | ...corrisponde al seguente |
|---|---|
| X?? | X, una sola volta oppure nessuna |
| X*? | X, zero o più volte |
| X+? | X, una o più volte |
Note
i quantificatori riluttanti rileveranno il minor numero di ripetizioni possibili. Per esempio, a+? rileverà la prima a in aaabbb
Table 17.10. Regex - Operatori logici
| Il costrutto | ...corrisponde al seguente |
|---|---|
| XY | X seguito da Y |
| X|Y | X oppure Y |
| (XY) | XY come gruppo singolo |
Sono disponibili diversi strumenti interattivi dedicati allo sviluppo e alla verifica delle espressioni regolari. Essi seguono quasi tutti lo stesso schema (vedere sotto l'esempio preso dal Regular Expression Tester): l'espressione regolare (voce in alto) analizza il testo da ricercare (riquadro al centro), restituendo i risultati, mostrati nel riquadro dei risultati.
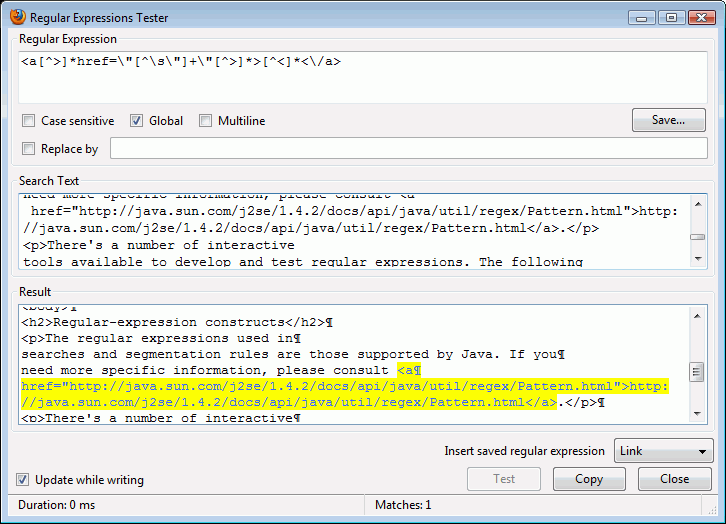
Per eseguire verifiche con uno strumento indipendente, nelle versioni per Windows, Linux, Mac e FreeBSD, usare The Regex Coach. Funziona in modo quasi identico all'esempio di cui sopra.
In OmegaT è pure presente una buona raccolta di utili esempi regex (si veda Opzioni > Segmentazione). L'elenco seguente include espressioni che potrebbero risultare utili quando si eseguono ricerche attraverso la memoria di traduzione:
Table 17.11. Regex - Esempi di espressioni regolari nelle traduzioni
| Espressione regolare | Trova il seguente: |
|---|---|
| (\b\w+\b)\s\1\b | doppie parole |
| [\.,]\s*[\.,]+ | virgola o punto, seguiti da spazi e ancora un'altra virgola o punto |
| \. \s+$ | spazi aggiuntivi dopo un punto alla fine di una riga |
| \s+a\s+[aeiou] | Inglese: le parole inizianti per vocali devono essere in genere precedute da "an" e non "a" |
| \s+an\s+[^aeiou] | Inglese: stesso controllo di cui sopra ma per le consonanti ("a", non "an") |
| \s{2,} | più di uno spazio |
| \.[A-Z] | Punto, seguito da una lettera maiuscola - forse uno spazio mancante tra un punto e l'inizio di una nuova frase? |
| \bis\b | cerca “is”, non “this” o “isn't”, ecc. |