Glosari su datoteke za korištenje u programu OmegaT, a koje izrađujete i ažurirate ručnim putem.
Ako neki projekt u sklopu programa OmegaT sadržava jedan ili više glosara, svi termini iz tekućega segmenta pronađeni u glosaru ili više njih automatski se prikazuju u oknu glosara.
Lokaciju i naziv glosara sami definirate u dijaloškome okviru svojstava projekta. Datotečni nastavak mora biti .txt ili .utf8, a ako ga nema, treba ga upisati. Datoteka glosara mora se nalaziti u mapi /glossary , ili pak u nekoj njenoj podmapi (npr. glossary/sub/glossary.txt). Datoteka ne mora nužno postojati, tj. biti unaprijed postavljena, jer se izrađuje (po potrebi) dodavanjem prve natuknice
glosara. Ako datoteka pak već postoji, ne obavlja se provjera njenoga formata ili znakovnoga skupa, a nove se natuknice uvijek
dodaju razdvojene tabulatorom i kodirane kao UTF-8. Budući da nema intervencija u postojećem sadržaju, ograničava se mogućnost
eventualnog oštećenja postojeće datoteke.
Postojeće glosare možete koristiti tako da ih jednostavno postavite u mapu /glossary nakon sastavljanja projekta. OmegaT po otvaranju projekta automatski otkriva datoteke glosara u toj mapi. Termini u tekućemu segmentu koje OmegaT pronađe u datoteci glosara (ili više njih) prikazuju se u oknu glosara.
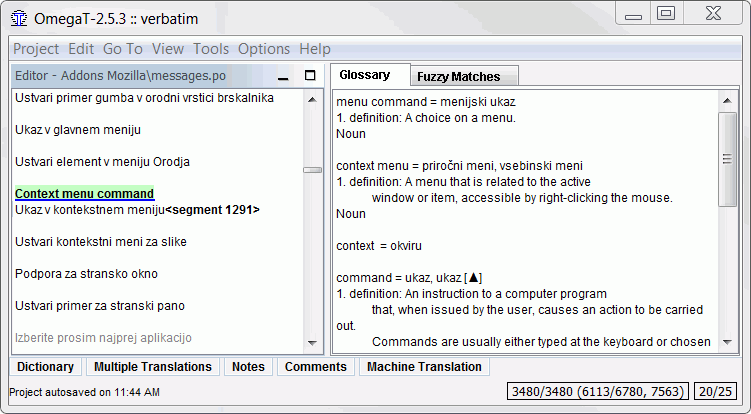
Izraz ispred znaka „=” je izvorišni termin, dok se ekvivalent (ili više njih) nalazi iza znaka „=”. Natuknicama glosara možete dodavati i komentare. Funkcija glosara pronalazi samo potpuno podudarne natuknice (pa tako, primjerice, ne pronalazi deklinirane oblike itd.). Nove je termine moguće i ručno dodavati u datoteku glosara (ili više njih) tijekom prevođenja, primjerice programom za obradu teksta. Netom dodani termini neće biti prepoznati sve do spremanja promjena u tekstnoj datoteci.
Izvorišni termin ne mora biti jednorječna natuknica, kao što možemo vidjeti u sljedećem primjeru:
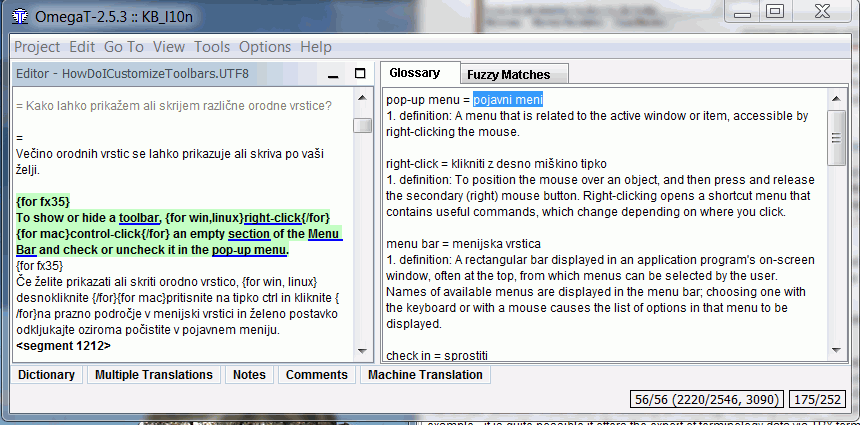
Podcrtana natuknica „pop-up menu” prikazana je u oknu glosara s ekvivalentom „pojavni meni”. Njenim označavanjem u oknu glosara i pritiskom desnom tipkom miša umećemo je u odredišni segment na trenutni položaj pokazivača miša.[1]
Glosari su datoteke jednostavnoga običnog teksta s popisima razdvojenim tabulatorom u tri stupca, pri čemu se izvorišni termin nalazi u prvome stupcu, a ekvivalent u drugome. Treći stupac možete koristiti za dodatne informacije. Moguće su i natuknice bez stupca ekvivalenata, tj. samo s izvorišnim terminom i komentarom.
Glosari se kodiraju automatski. Po naravi stvari, kodiranje mora odgovarati obama jezicima pa se stoga preporučuje unicode.
Podržan je i format CSV. Taj je format isti kao i onaj s razdvajanjem tabulatorom, osim što su izvorišni termini i ekvivalenti razdvojeni zarezom. Polja komentara također su razdvojena zarezom („,”). Nizove je moguće staviti u navodnike ("), što omogućava zareze unutar nizova, npr.:
"This is a source term, which contains a comma","Ovo je izvorišni termin, a sadržava zarez"
Pored formata običnoga teksta, podržan je i TBX, kao format glosara samo za čitanje. Datoteka .tbx se mora nalaziti u mapi /glossary, ili pak u nekoj njenoj podmapi (npr. glossary/sub/MojGlosar.tbx).
TBX (Term Base eXchange) je otvorena međunarodna norma koju su odobrile organizacije LISA i ISO. Temelji se na XML-u, a namijenjena je za razmjenu strukturiranih terminoloških podataka. Ako imate neki sustav za upravljanje terminologijom, velika je vjerojatnost da vam on nudi i izvoz terminoloških podataka u format TBX. Microsoftova terminološka zbirka je na raspolaganju za preuzimanje na skoro 100 jezika, a može poslužiti kao ključni glosar za informatičku tehnologiju.
Napomena: izgleda da baze u formatu .tbx izvezene programom MultiTerm nisu pouzdane (prema stanju iz studenoga 2013.) pa je bolje umjesto toga koristiti izvoz u formatu
.tab, koji MultiTerm također nudi.
Postavke projekta omogućavaju upisivanje naziva datoteke zapisivoga glosara (pogledajte početak ovoga poglavlja). Za dodavanje nove natuknice pritisnite desnom tipkom miša u oknu glosara ili pritisnite Ctrl+Shift+G. Otvorit će se dijaloški okvir u koji možete upisati izvorišni termin, ekvivalent i eventualni komentar.
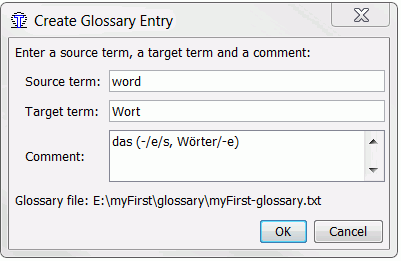
Sadržaj datoteka glosara čuva se u memoriji i učitava otvaranjem projekta. Dopunjavanje glosara zapravo je vrlo jednostavno: pritisnite Ctrl+Shift+G i unesite novi termin, njegov ekvivalent i komentare po želji (s tim da pazite da za prijelaz na sljedeće polje pritisnete tipku Tab), a potom spremite uneseno. Sadržaj okna glosara ažurira se u skladu s upisanim.
Lokaciju datoteke zapisivoga glosara možete odrediti u dijaloškome okviru Podržane su datoteke s datotečnim nastavcima TXT i UTF8
Napomena: naravno, ima i drugih načina i programa za izradu jednostavnih datoteka s natuknicama razdvojenim tabulatorom. Nikakva se kritika ne može uputiti korištenju programa Notepad++ u sustavu Windows, GEdit na Linuxu, kao ni nekom programu za rad s proračunskim tablicama: možete koristiti svaki program koji omogućava rad s datotekama kodiranim kao UTF-8 (ili UTF-16 LE) i koji prikazuje bjeline (kako vam ne bi promaknuo obavezni TAB).
Rezultati pretraživanja prioritetnoga glosara (prema zadanim vrijednostima to je glossary/glossary.txt) prikazuju se na vrhu popisa u oknu glosara i u Savjetniku.
Budući da natuknice mogu biti mješavina izvora iz prioritetnoga i neprioritetnih glosara, oni iz prioritetnoga glosara prikazuju se u obliku podebljanoga teksta.
Podaci izvezeni programom Trados MultiTerm mogu se koristiti kao glosari u programu OmegaT bez dodatnih izmjena, pod uvjetom da imaju datotečni nastavak .tab i da prva dva polja sadržavaju izvorišni termin i ekvivalent. Ako podatke izvozite prema ponuđenoj funkciji razdvajanja tabulatorom
(„tab-delimited export”), trebate izbrisati prvih pet stupaca koje stvara program (Seq. Nr, Date created itd).
Problem kada se ne prikazuju termini iz glosara – mogući uzroci:
-
Nema datoteka glosara u mapi „glossary”.
-
Datoteka glosara je prazna.
-
Natuknice nisu razdvojene tabulatorom.
-
Datoteka glosara nema odgovarajući datotečni nastavak (.tab, .utf8, .txt ili .tbx).
-
Natuknice glosara i termina u izvorišnome tekstu dokumenta ne podudaraju se u cijelosti; vjerojatno se radi o razlikama u rodu/broju/padežu.
-
Datoteka glosara nije odgovarajuće kodirana.
-
U tekućemu segmentu nema termina koji se podudaraju s nekom natuknicom u glosaru.
-
Svi su problemi uklonjeni, ali projekt nije ponovno učitan.
Problem kada se neki se znakovi ne prikazuju pravilno u oknu glosara...
-
...dok se istodobno pravilno prikazuju u oknu za obradu: radi se o neodgovarajućemu datotečnom nastavku i kodiranju datoteke.
[1] Napominjemo da to u navedenome slučaju predstavlja tek polovicu priče (ili čak možda ni toliko), budući da odredišni jezik (slovenski) koristi deklinaciju. Stoga umetnuti ekvivalent „pojavni meni” u nominativu valja promijeniti u lokativ – „pojavnem meniju”. To znači da je vjerojatno brže ako odmah pravilno otipkamo termin bez korištenja glosara i njegovih prečaca.