Glosáře představují soubory, které jsou pro použití v OmegaT tvořené a aktualizované ručně.
Pokud projekt OmegaT obsahuje jeden či více glosářů, jakékoliv termíny v glosáři, pokud jsou nalezené v aktuálním segmentu, budou automaticky zobrazené v okně Glosář.
Sami si zvolíte umístění a název svého glosáře v dialogovém okně Vlastnosti projektu. Koncovka musí být .txt nebo .utf8 (pokud chybí, bude přidána). Umístění tohoto souboru musí být sice v adresáři /glossary, ale zato může být na jakékoliv nižší úrovni (např. glossary/sub/glossary.txt). Soubor glosáře nemusí existovat v době vytváření adresáře, samotný soubor glosáře bude vytvořen (pokud nutno) přidáním
prvního záznamu. Pokud už máte soubor glosáře k dispozici, program nebude ověřovat formát nebo znakovou sadu: nové záznamy
budou vždy ve formátu, kdy jsou záznamy od sebe odděleny tabulátorem a kódování bude UTF-8. Protože se nezasahuje do již existujícího
obsahu, je též omezeno riziko poškození již existujícího souboru.
Dostupný glosář začněte používat tak, že jej po vytvoření projektu jednoduše umístíte do adresáře /glossary. Když je projekt otevřený, OmegaT v tomto adresáři soubory glosáře automaticky detekuje. Výrazy aktuálního segmentu, které OmegaT najde v souboru (souborech) glosáře, se zobrazují v okně Glosář:
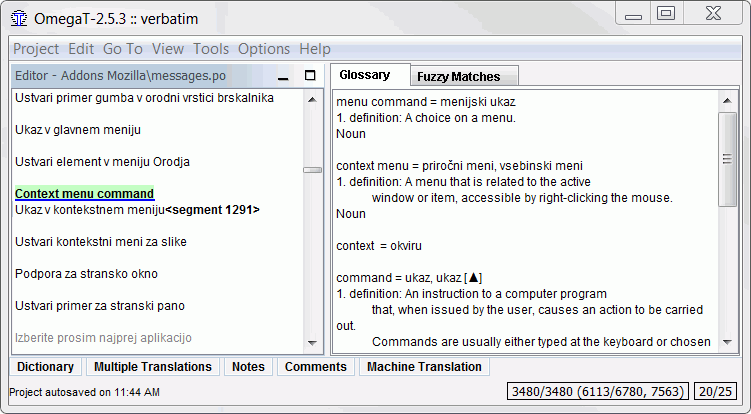
Slovo před znakem rovnítka (=) je termín zdrojového jazyka a jeho překlad (překlady) jsou za rovnítkem. K záznamu v glosáři můžete přidat komentář. Funkce glosáře nalezne jen takové výrazy, pokud se záznam v glosáři přesně shoduje se slovem v překládaném textu (např. nenalezne skloňované tvary atd.). Nové záznamy mohou být ručně přidány do souboru nebo souborů glosáře v průběhu překladu. Nově vložené pojmy budou rozpoznané až po novém načtení projektu.
Termín ve zdrojovém jazyce nemusí být položka o jednom slovu, jak to vidíme na příkladě:
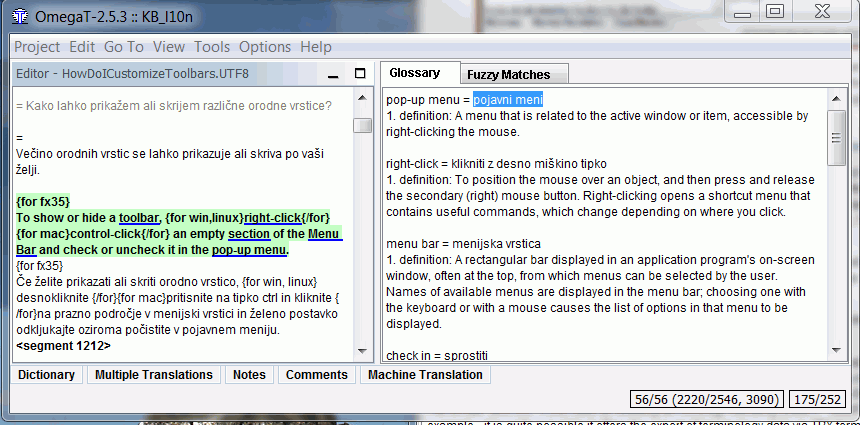
Podtržené slovo „pop-up menu“ může být v glosáři nalezeno jako „pojavni menu“. V glosáři nalezený záznam vložíte do překladu tak, že označíte termín v podokně Glosáře a kliknete pravým tlačítkem (nebo kolečkem) myši do cílového segmentu.[1]
Soubory glosáře představují jednoduché soubory v prostém textu a obsahují tři tabulátorem oddělené sloupce, ve kterých se nachází zdrojový (první sloupec) a cílový (druhý sloupec) výraz. Třetí sloupec může být použit pro dodatečné informace. Také můžete mít záznamy, kde chybí sloupec s překladem, tj. záznamy jen s nějakým pojmem a příslušný komentář.
Kódování glosářů je určováno automaticky. Kódování se zajisté musí shodovat s oběma obsaženými jazyky, proto je doporučováno použít Unicode.
Formát CSV je také podporován. Tento formát je prakticky to samé jako když jsou položky odděleny tabulátorem: zdrojový výraz, cílový výraz. Pole s komentářem je odděleno čárkou ','. Jednotlivé řetězce mohou být ohraničeny uvozovkami ", což umožňuje použít čárku uvnitř řetězce.
„Toto je zdrojový výraz, který obsahuje čárku“, „c'est un terme, qui contient une virgule“
Vedle prostého textového formátu je podporován formát TBX jakožto formát slovníku určený pouze pro čtení.. Umístění souboru .tbx musí být sice v adresáři /glossary, ale zato může být na jakékoliv nižší úrovni (např. glossary/sub/MujGlosar.txt).
TBX - Term Base eXchange - je otevřený standard založený na XML a slouží k výměně strukturovaných dat, TBX se osvědčil jako mezinárodní standard organizací LISA a ISO. Pokud používáte systém pro správu terminologie je docela možné, že bude nabízet export terminologických dat do formátu TBX. Sbírka terminologických slovníčků Microsoft Terminology Collection nabízí ke stažení terminologii v téměř stech jazycích a slouží jako základ IT glosáře.
Poznámka: koncovka .tbx souborů MultiTerm se zdá být nespolehlivá (listopad 2013), doporučujeme místo ní raději používat pro MultiTerm kocovku .tab
Při nastavování projektu je možno zadat název pro zapisovatelný soubor glosáře (viz začátek této kapitoly). Kliknutím pravým tlačítkem myši v okně glosáře, nebo stiskem klávesové zkratky Ctrl+Shift+G se přidává nový záznam. Otevře se dialogové okno, které umožní vložit zdrojový pojem, překlad a také v případě zájmu i komentář.

Obsah souboru glosáře je přístupný v paměti a je nahrán když se otevírá nebo znovu načítá projekt. Aktualizace glosáře je tedy zcela jednoduchá: stiskněte Ctrl+Shift+G a zadejte nový termín, jeho překlad a příslušný komentář (ujistěte se, že jste stiskli tabulátor pro přechod mezi jednotlivými poli) a soubor uložte. Současně bude aktualizován obsah podokna Glosář.
Umístění zapisovatelného souboru glosáře si můžete nastavit přes dialog Rozeznatelné koncovky jsou TXT a UTF8.
Poznámka: Jistě že jsou tu i jiné způsoby a prostředky jak vytvořit prostý soubor se záznamy oddělenými tabulátorem. Pro tyto účely můžete používat například Notepad++ pod Windows, GEdit na Linuxu nebo nějaký tabulkový procesor: lze použít jakoukoliv aplikaci, která umí pracovat s UTF-8 (nebo UTF-16 LE), a která umí zobrazit netisknutelné znaky (takže vám nebude chybět značka tabulátoru TAB).
Výsledky hledání z prioritního glosáře (ve výchozím nastavení je to soubor glossary/glossary.txt) se zobrazují na prvním místě v podokně Glosář a pro TransTips.
Když se mezi zobrazenými záznamy vyskytují slova z prioritních a neprioritních glosářů, pak jsou slova z prioritních glosářů zobrazena tučně.
Data, která jsou exportována z Trados MutliTerm můžete použít jako glosáře OmegaT bez dalších úprav, tedy jestliže mají koncovku .tab a pole pro zdroj a překlad jsou prvními dvěma poli (v tomto pořadí). Když exportujete data použitím možnosti „Tab-delimited
export“, budete muset smazat prvních 5 sloupců (Seq. Nr, Date created atd.).
Problém: Nezobrazují se žádné termíny z glosáře.
-
V adresáři „glossary“ není umístěn žádný glosář.
-
Soubor glosáře je prázdný.
-
Položky glosáře nejsou od sebe odděleny tabulátorem.
-
Soubor glosáře nemá správnou koncovku (.tab, .utf8 nebo .txt).
-
Není nalezena PŘESNÁ shoda mezi záznamem v glosáři a zdrojovým textem ve vašem dokumentu – například když je daná položka v množném čísle.
-
Soubor glosáře nemá správné kódování.
-
V aktuálním segmentu nejsou žádné termíny, které se kryjí s termíny v glosáři.
-
Jeden nebo více z nahoře zmíněných problémů byl vyřešen, ale projekt nebyl nově načten.
Problém: V podokně Glosář se některé znaky nezobrazují správně
-
... ale stejné znaky v okně Editoru jsou zobrazeny správě: koncovka a kódování si neodpovídají.
[1] Ve výše uvedeném případě jsme si k věci neřekli vše, protože cílový jazyk (zde slovinština) používá deklinaci. Takže vložený výraz „pojavni menu“ ve tvaru nominativu musí být změněno na „pojavnem meniju“, tj. tvar lokativu. Je tedy pravděpodobně rychlejší daný pojem napsat hned správně bez kroku navíc vkládat termín z glosáře, byť pomocí klávesové zkratky, a vyhnout se těmto úprávám.