文字列検索と分節化規則で使用する正規表現は、Java がサポートしているものです。より詳細な情報については Java の正規表現に関する技術文書を参照してください。以下の構文一覧と使用例も参照してください。
注記
この章は上級者のユーザーを対象にしています。独自の分節化規則を定義したり、こみいった条件での検索を必要とする場合に、参照してください。
表17.2 正規表現 - 文字
| 構文 | 一致対象 |
|---|---|
| x | 文字 x(以下に示すもの以外) |
| \uhhhh | 16 進値 0xhhhh を持つ文字 |
| \t | タブ文字('\u0009') |
| \n | 改行(ラインフィード、LF)文字('\u000A') |
| \r | キャリッジリターン(CR)文字('\u000D') |
| \f | 用紙送り文字('\u000C') |
| \a | 警告 (ベル) 文字('\u0007') |
| \e | エスケープ文字('\u001B') |
| \cx | x に対応する制御文字 |
| \0n | 8 進値 0n を持つ文字(0 <= n <= 7) |
| \0nn | 8 進値 0nn を持つ文字(0 <= n <= 7) |
| \0mnn | 8 進値 0mnn を持つ文字(0 <= m <= 3、0 <= n <= 7) |
| \xhh | 16 進値 0xhh を持つ文字 |
表17.3 正規表現 - 引用
| 構文 | 一致対象 |
|---|---|
| \ | 次の文字をエスケープします。以下のメタ文字(!$()*+.<>?[\]^{|})自体を一致対象としたい場合に入力が必要です |
| \\ | たとえば、この構文ではバックスラッシュ文字を表します |
| \Q | \E までのすべての文字をエスケープします |
| \E | \Q で開始された引用をエスケープします |
表17.5 正規表現 - 文字クラス
| 構文 | 一致対象 |
|---|---|
| [abc] | a、b または c(単純クラス) |
| [^abc] | a、b、c 以外の文字(否定) |
| [a-zA-Z] | a 〜 z または A から Z(範囲) |
表17.6 正規表現 - 定義済みの文字クラス
| 構文 | 一致対象 |
|---|---|
| . | 任意の文字(行末記号を除く) |
| \d | 数字:[0-9] |
| \D | 数字以外:[^0-9] |
| \s | 空白文字:[ \t\n\x0B\f\r] |
| \S | 非空白文字:[^\s] |
| \w | 単語構成文字:[a-zA-Z_0-9] |
| \W | 非単語文字:[^\w] |
注記
最長一致数量子は、指定した文字となるべく多い文字数で一致します。たとえば a+? は文字列 aaabbb にある aaa と一致します。
注記
最短一致数量子は、指定した文字となるべく少ない文字数で一致します。たとえば a+? は文字列 aaabbb にある最初の a と一致します。
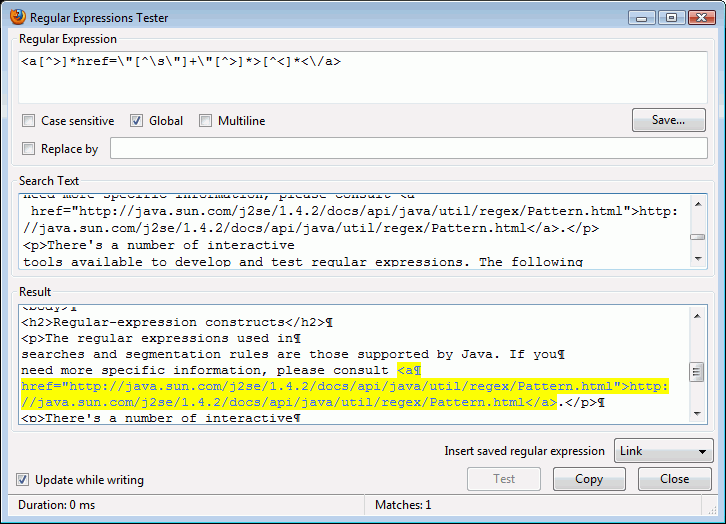
正規表現の作成やテストを行える対話式のツールは、たくさんあります。それらのツールは、たいてい同じ使い方ができます(実例は、下の Regular Expression Tester を参照してください)。入力した正規表現(図では最上段の「Regular Expression」)にしたがって対象テキスト(中段の「Search Text」)を検索し、その結果(下段の「Result」)を表示します。
Windows、Linux、FreeBSD 向けの単体ツールを探しているなら、The Regex Coach を確認してみてください。このツールは、上の例(Firefox アドオン)とほとんど同じように使えます。
正規表現の便利な構文例は、OmegaT 自体にも含まれています([設定]→[分節化規則...]を参照してください)。以下は、特に翻訳メモリを検索する場合に便利な正規表現の一覧です:
表17.11 正規表現 - 翻訳で使える正規表現例
| 正規表現 | 検索対象 |
|---|---|
| (\b\w+\b)\s\1\b | 重複している単語 |
| [\.,]\s*[\.,]+ | カンマまたはピリオドの後ろに、0個以上のスペースが続いて、再びカンマまたはピリオド |
| \. \s+$ | 行末で、ピリオドの後ろに余分なスペースがある箇所 |
| \s+a\s+[aeiou] | 英語:母音で始まる単語の前に「an」でなく「a」がある箇所 |
| \s+an\s+[^aeiou] | 英語:子音で始まる単語の前に「a」でなく「an」がある箇所 |
| \s{2,} | 2 個以上の空白 |
| \.[A-Z] | ピリオドの直後に大文字が続く箇所 - 新しい文章の前の空白が欠落している可能性あり? |
| \bis\b | 「is」を検索(「this」や「isn't」などに一致させない) |